Netflix App Testing At Scale
Jose Alcérreca on 2025-04-08

Netflix App Testing At Scale
This is part of the Testing at scale series of articles where we asked industry experts to share their testing strategies. In this article, Ken Yee, Senior Engineer at Netflix, tells us about the challenges of testing a playback app at a massive scale and how they have evolved the testing strategy since the app was created 14 years ago!
Introduction
Testing at Netflix continuously evolves. In order to fully understand where it’s going and why it’s in its current state, it’s also important to understand the historical context of where it has been.
The Android app was started 14 years ago. It was originally a hybrid application (native+webview), but it was converted over to a fully native app because of performance issues and the difficulty in being able to create a UI that felt/acted truly native. As with most older applications, it’s in the process of being converted to Jetpack Compose. The current codebase is roughly 1M lines of Java/Kotlin code spread across 400+ modules and, like most older apps, there is also a monolith module because the original app was one big module. The app is handled by a team of approximately 50 people.
At one point, there was a dedicated mobile SDET (Software Developer Engineer in Test) team that handled writing all device tests by following the usual flow of working with developers and product managers to understand the features they were testing to create test plans for all their automation tests. At Netflix, SDETs were developers with a focus on testing; they wrote Automation tests with Espresso or UIAutomator; they also built frameworks for testing and integrated 3rd party testing frameworks. Feature Developers wrote unit tests and Robolectric tests for their own code. The dedicated SDET team was disbanded a few years ago and the automation tests are now owned by each of the feature subteams; there are still 2 supporting SDETs who help out the various teams as needed. QA (Quality Assurance) manually tests releases before they are uploaded as a final “smoke test”.
In the media streaming world, one interesting challenge is the huge ecosystem of playback devices using the app. We like to support a good experience on low memory/slow devices (e.g. Android Go devices) while providing a premium experience on higher end devices. For foldables, some don’t report a hinge sensor. We support devices back to Android 7.0 (API24), but we’re setting our minimum to Android 9 soon. Some manufacturer-specific versions of Android also have quirks. As a result, physical devices are a huge part of our testing
Current Testing Approach
As mentioned, feature developers now handle all aspects of testing their features. Our testing layers look like this:
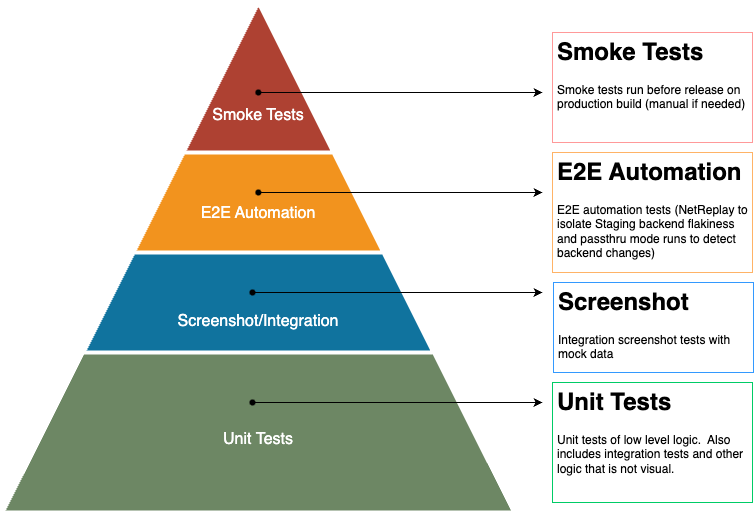
However, because of our heavy usage of physical device testing and the legacy parts of the codebase, our testing pyramid looks more like an hourglass or inverted pyramid depending on which part of the code you’re in. New features do have this more typical testing pyramid shape.
Our screenshot testing is also done at multiple levels: UI component, UI screen layout, and device integration screen layout. The first two are really unit tests because they don’t make any network calls. The last is a substitute for most manual QA testing.
Unit Test Frameworks
Unit tests are used to test business logic that is not dependent on any specific device/UI behavior. In older parts of the app, we use RxJava for asynchronous code and streams are tested. Newer parts of the app use Kotlin Flows and Composables for state flows which are much easier to reason about and test compared to RxJava.
Frameworks we use for unit testing are:
- Strikt: for assertions because it has a fluent API like AssertJ but is written for Kotlin
- Turbine: for the missing pieces in testing Kotlin Flows
- Mockito: for mocking any complex classes not relevant for the current Unit of code being tested
- Hilt: for substituting test dependencies in our Dependency Injection graph
- Robolectric: for testing business logic that has to interact in some way with Android services/classes (e.g., parcelables or Services)
- A/B test/feature flag framework: allows overriding an automation test for a specific A/B test or enabling/disabling a specific feature
Flakiness in Unit Tests
Because unit tests are blocking in our CI pipeline, minimizing flakiness is extremely important. There are generally two causes for flakiness: leaving some state behind for the next test and testing asynchronous code.
JVM (Java Virtual Machine) Unit test classes are created once and then the test methods in each class are called sequentially; instrumented tests in comparison are run from the start and the only time you can save is APK installation. Because of this, if a test method leaves some changed global state behind in dependent classes, the next test method can fail. Global state can take many forms including files on disk, databases on disk, and shared classes. Using dependency injection or recreating anything that is changed solves this issue.
With asynchronous code, flakiness can always happen as multiple threads change different things. Test Dispatchers (Kotlin Coroutines) or Test Schedulers (RxJava) can be used to control time in each thread to make things deterministic when testing a specific race condition. This will make the code less realistic and possibly miss some test scenarios, but will prevent flakiness in the tests.
Screenshot Test Frameworks
Screenshot testing frameworks are important because they test what is seen vs. testing behavior. As a result, they are the best replacement for manual QA testing of any screens that are static (animations are still difficult to test with most screenshot testing frameworks unless the framework can control time).
We use a variety of frameworks for screenshot testing:
- Paparazzi: for Compose UI components and screen layouts; network calls can’t be made to download images, so you have to use static image resources or an image loader that draws a pattern for the requested images (we do both)
- Localization screenshot testing: captures screenshots of screens in the running app in all locales for our UX teams to verify manually
- Device screenshot testing: device testing used to test visual behavior of the running app
Device Test Frameworks
Finally, we have device tests. As mentioned, these are magnitudes slower than tests that can run on the JVM. They are a replacement for manual QA and used to smoke test the overall functionality of the app.
However, since running a fully working app in a test has external dependencies (backend, network infra, lab infra), the device tests will always be flaky in some way. This cannot be emphasized enough: despite having retries, device automation tests will always be flaky over an extended period of time. Further below, we’ll cover what we do to handle some of this flakiness.
We use these frameworks for device testing:
- Espresso: majority of device tests use Espresso which is Android’s main instrumentation testing framework for user interfaces
- PageObject test framework: internal screens are written as PageObjects that tests can control to ease migration from XML layouts to Compose (see below for more details)
- UIAutomator: a small “smoke test” set of tests uses UIAutomator to test the fully obfuscated binary that will get uploaded to the app store (a.k.a., Release Candidate tests)
- Performance testing framework: measures load times of various screens to check for any regressions
- Network capture/playback framework: allows playback of recorded API calls to reduce instability of device tests
- Backend mocking framework: tests can ask the backend to return specific results; for example, our home page has content that is entirely driven by recommendation algorithms so a test can’t deterministically look for specific titles unless the test asks the backend to return specific videos in specific states (e.g. “leaving soon”) and specific rows filled with specific titles (e.g. a Coming Soon row with specific videos)
- A/B test/feature flag framework: allows overriding an automation test for a specific A/B test or enabling/disabling a specific feature
- Analytics testing framework: used to verify a sequence of analytics events from a set of screen actions; analytics are the most prone to breakage when screens are changed so this is an important thing to test.
The PageObject design pattern started as a web pattern, but has been applied to mobile testing. It separates test code (e.g. click on Play button) from screen-specific code (e.g. the mechanics of clicking on a button using Espresso). Because of this, it lets you abstract the test from the implementation (think interfaces vs. implementation when writing code). You can easily replace the implementation as needed when migrating from XML Layouts to Jetpack Compose layouts but the test itself (e.g. testing login) stays the same.
In addition to using PageObjects to define an abstraction over screens, we have a concept of “Test Steps”. A test is composed of test steps. At the end of each step, our device lab infra will automatically create a screenshot. This gives developers a storyboard of screenshots that show the progress of the test. When a test step fails, it’s also clearly indicated (e.g., “could not click on Play button”) because a test step has a “summary” and “error description” field.
Device Automation Infrastructure

Netflix was probably one of the first companies to have a dedicated device testing lab; this was before 3rd party services like Firebase Test Lab were available. Our lab infrastructure has a lot of features you’d expect to be able to do:
- Target specific types of devices
- Capture video from running a test
- Capture screenshots while running a test
- Capture all logs
- Cellular tower so we can test wifi vs. cellular connections; Netflix has their own physical cellular tower in the lab that the devices are configured to connect to.
- Network conditioning so slow networks can be simulated
- Automatic disabling of system updates to devices so they can be locked at a specific OS level
- Only uses raw adb commands to install/run tests (all this infrastructure predates frameworks like Gradle Managed Devices or Flank)
- Running a suite of automated tests against an A/B tests
- Test hardware/software for verifying that a device doesn’t drop frames for our partners to verify their devices support Netflix playback properly; we also have a qualification program for devices to make sure they support HDR and other codecs properly.
Handling Test Flakiness
As mentioned above, test flakiness is one of the hardest things about inherently unstable device tests. Tooling has to be built to:
- Minimize flakiness
- Identify causes of flakes
- Notify teams that own the flaky tests
- Automatically identifies the PR (Pull Request) batch that a test started to fail in and notifies PR authors that they caused a test failure
- Tests can be marked stable/unstable/disabled instead of using @Ignore annotations; this is used to disable a subset of tests temporarily if there’s a backend issue so that false positives are not reported on PRs
- Automation that figures out whether a test can be promoted to Stable by using spare device cycles to automatically evaluate test stability
- Automated IfTTT (If This Then That) rules for retrying tests or ignoring temporary failures or repairing a device
- Failure report let us easily filter failures according to what device maker, OS, or cage the device is in, e.g. this shows how often a test fails over a period of time for these environmental factors:
- Failure report lets us triage error history to identify the most common failure reasons for a test along with screenshots:
- Tests can be manually set up to run multiple times across devices or OS versions or device types (phone/tablet) to reproduce flaky tests
We have a typical PR (Pull Request) CI pipeline that runs unit tests (includes Paparazzi and Robolectric tests), lint, ktLint, and Detekt. Running roughly 1000 device tests is part of the PR process. In a PR, a subset of smoke tests is also run against the fully obfuscated app that can be shipped to the app store (the previous device tests run against a partially obfuscated app).
Extra device automation tests are run as part of our post-merge suite. Whenever batches of PRs are merged, there is additional coverage provided by automation tests that cannot be run on PRs because we try to keep the PR device automation suite under 30 minutes.
In addition, there are Daily and Weekly suites. These are run for much longer automation tests because we try to keep our post-merge suite under 120 minutes. Automation tests that go into these are typically long running stress tests (e.g., can you watch a season of a series without the app running out of memory and crashing?).
In a perfect world, you have infinite resources to do all your testing. If you had infinite devices, you could run all your device tests in parallel. If you had infinite servers, you could run all your unit tests in parallel. If you had both, you could run everything on every PR. But in the real world, you have a balanced approach that runs “enough” tests on PRs, postmerge, etc. to prevent issues from getting out into the field so your customers have a better experience while also keeping your teams productive.
Coverage
Coverage on devices is a set of tradeoffs. On PRs, you want to maximize coverage but minimize time. On post-merge/Daily/Weekly, time is less important.
When testing on devices, we have a two dimensional matrix of OS version vs. device type (phone/tablet). Layout issues are fairly common, so we always run tests on phone+tablet. We are still adding automation to foldables, but they have their own challenges like being able to test layouts before/after/during the folding process.
On PRs, we normally run what we call a “narrow grid” which means a test can run on any OS version. On Postmerge/Daily/Weekly, we run what we call a “full grid” which means a test runs on every OS version. The tradeoff is that if there is an OS-specific failure, it can look like a flaky test on a PR and won’t be detected until later.
Future of Testing
Testing continuously evolves as you learn what works or new technologies and frameworks become available. We’re currently evaluating using emulators to speed up our PRs. We’re also evaluating using Roborazzi to reduce device-based screenshot testing; Roborazzi allows testing of interactions while Paparazzi does not. We’re building up a modular “demo app” system that allows for feature-level testing instead of app-level testing. Improving app testing never ends…